Discovery Summit
Discovery SummitDSJ2022
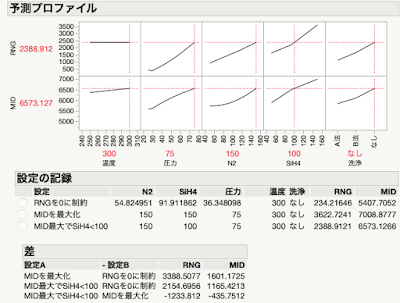
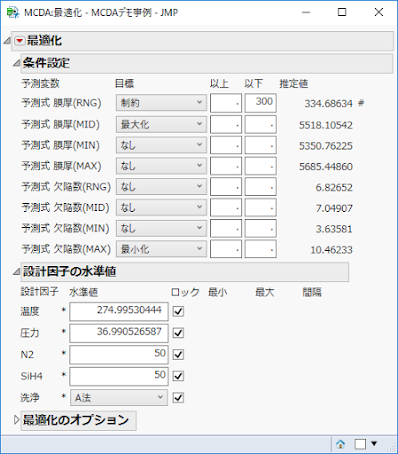
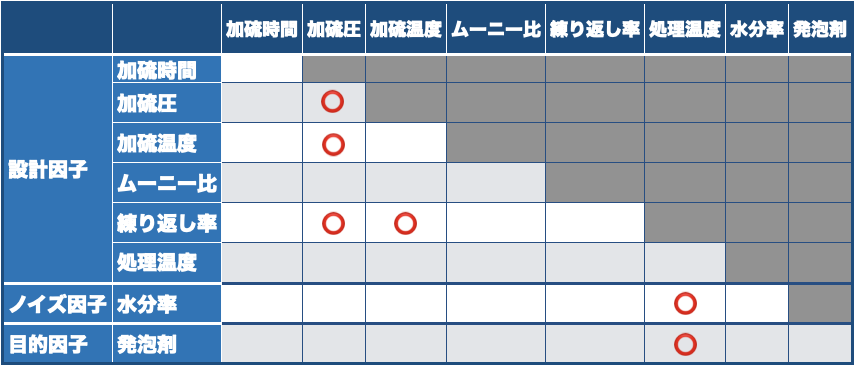
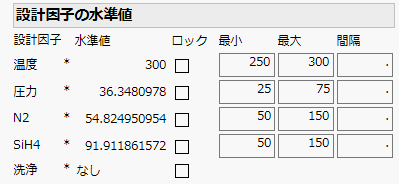
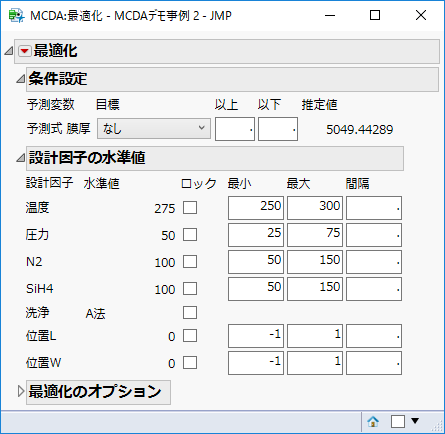
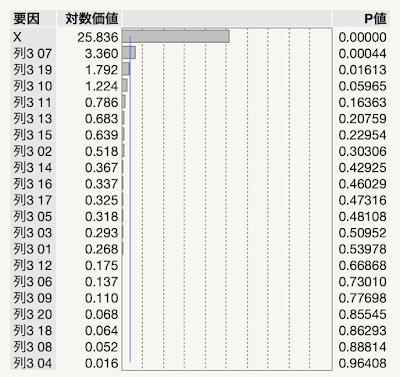
先週再再されたDiscovery Summit Japan 2022では,JMP17の新機能を色々と勉強できたわけですが,近年では最も大きなバージョンアップとなったようです.特に「ワークフロービルダー」と「ナビ付きDOE」の二つが大きな目玉でしょうか? 「ナビ付きDOE」は英語版では「Easy DOE」であって米国SAS社のプレゼンでもそのように呼んでいましたね.「ナビ付きDOE」という翻訳はよく考えられたのでしょうけれど,このプラットフォームは実験計画の作成をするものだから,自分としては「DOEナビゲーター」とかにして欲しかったです.「イージー実験計画」とかの直訳よりはマシですけど....