 JMP
JMP カテゴライズについて
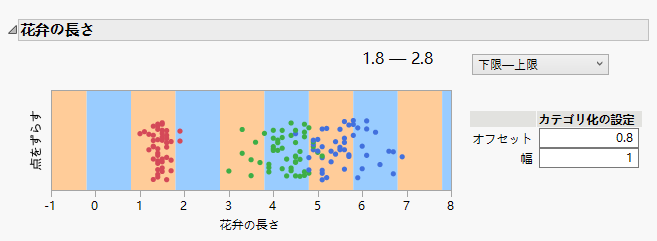
ご質問を頂いたので,今日はそれについてお答え,といったらいいのか補足といったらいいのかわからないけど,を書きます.詳細は伏せるけど,データの観測値が階級範囲でくくられているけど,もとの連続量に戻したほうがよいか?という質問.ローデータでは連続尺度の変数だったのが,前処理の過程で順序尺度化されているケースです.そりゃ不可逆だから,ローデータが入手できればそれに越したことないのは明らかだよね.これだけだと素気ないから,以下思ってることをダラダラと書きます. 英語ではカテゴライズと呼ぶことが多いけど,その特殊なケースがヒストグラムを描くために階級間隔を決めて,観測値を分類すること.exclusive...