
先日は某社で実験計画についてお話しする機会がありました.関係者の皆様,貴重な体験をさせていただきありがとうございました.時間がない中で詰め込みすぎた感があるので,後日何か疑問が湧きましたらいつでもご連絡ください.大阪の会社だったのであまり馴染みのない大阪の街を歩き回ったのですが,電車の中で大声で話している人がいて喧しかったり,コンビニの前で大勢の人がタバコを吸ってたむろっていたり,おっちゃんが自転車で暴走していたり,久しぶりの大阪は賑やかでした.歴史的な建造物もちらほらあって,重みも感じてよかったです.今まで行ったことがある大阪は大阪大学だったり,SAS社のサテライトだったり北寄りで,今回もどちらかというとキタなので,これらの偏ったサンプリングでは真の大阪像は予測できません.機会があればミナミのサンプリングもしてみたいなと思っています.
講演には『統計的問題解決入門』で勉強してくださったり,このブログをお読みいただいている方もいらっしゃったので,気恥ずかしい思いをいたしましたが,みなさんよく聞いてくださったので,思い切ってお引き受けしてよかったと思っています.とはいえ,人前で話すのは得意ではないので毎回緊張しますし,特に今回のように宿泊が伴うとホテルで寝られない質の私としては大変疲れました.今週は分析の交渉力について書く予定にしていましたが,しんどいので本日はメールでいただいた質問にお答えする形で,オーバーフィッティングについて話します.ご存知の方には当たり前なので,申し訳ないのですが,中高生向きの初心者用コンテンツとしてご容赦ください.
現象としてオーバーフィッティングを確認するのは簡単です.むやみにべき乗項を加えることの禁忌は容易に理解できると思いますので,別の例を示します.例えば,以下の手順で新規データテーブルに列を作ってみてください.
1.「データの初期化」を「シーケンスデータ」に変更して「列の新規作成」します.(設定値はデフォルトのまま)列名は「X」とでも.
2.「Y」列を新規作成し「計算式」として例えば以下の数式を入力します.
:X + Random Normal() * 20
この計算式には「Random Normal」関数で乱数が組み込まれています.
3.今度は「データの初期化」を「乱数」にして「追加する列の数」を20にして「列の新規作成」します.列名はデフォルトで「列3 01」から「列3 20」となります.この列は「Y」とは無関係な単なるノイズです.
4.「モデルのあてはめ」で「Y」を『Y』に「X」と「列3 01」から始まる20列を「モデル効果」に『追加』して『実行』します.主効果のみにしてください.
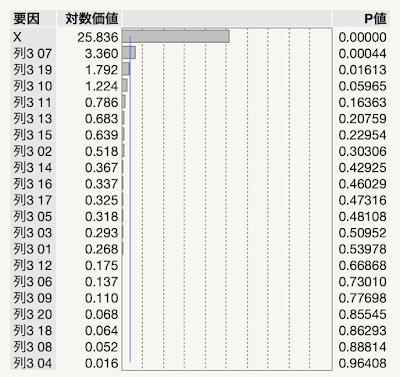
レポートの「効果の要約」を見てください.「X」以外の要因が有意になっていませんか.もしなっていなかったならば「やり直し>自動再計算」にチェックを入れて,「Y」の計算式の『適用』を繰り返し押して乱数を変えてみてください.おそらく,そのうち冒頭のように何かしら有意な列が出てくるはずです.この例では「列3 07」が有意となっていますが,何しろ単なる乱数列なので明らかに間違った効果です.このように,効果の数が多くなればたとえ意味のない変数であっても見かけ上の関係が出てきてしまいます.これがオーバーフィッティングの怖さです.観測データにはノイズが含まれているため,データを完璧に記述するモデルはノイズも正確に再現しています.これが災いの元です.ノイズは再現しないからノイズなのです.
オーバーフィッティングは機械学習では過学習のことです.学習しすぎるとかえって役に立たなくなるのは人間も同じです.記憶は生存に直結しているとはいえ,人間は忘れることで生き延びてきました.例えば私たちの祖先の猿が獣に襲われたとします.命からがら逃げ延びたとして,その記憶が生存に役立つには細部を忘れることが重要でした.例えば「夏の初めの朝に,森の外れの見通しの良い草原で,尻尾が長く片耳の垂れた黒い縞模様のある黄色い四つ足の生き物に,飛びかかるように襲われた.」と小説のように5W1Hで細部を詳細に覚えていた猿は恐らくその後その経験を生かせなかったことでしょう.詳細な記憶は生存には役に立たないどころか,逆に弊害をもたらします.この記憶を正確に覚えていた記憶力優秀な猿は,秋の夕方に黒い獣に襲われてしまったかもしれません.忘れっぽかった猿は見通しの良い草原で敵に襲われたという記憶のみを保持していたため,生存に役立ったかもしれません.少なくとも詳細を忘れたことは生存レースに有利に働いたことは間違いありません.忘れっぽかった猿の子孫である私たちも同様に忘れっぽいはずです.
話が逸れましたが,統計モデリングにおいても,良いモデルを作るには詳細を忘れることが重要です.データを完璧に説明したモデルは予測には役に立たないのです.特に説明変数が多いと目的変数をいかようにも説明できてしまうので,真の母集団にない関係をあたかもあるように見せてしまうことが可能です.この間違いを回避するには,できるだけ少ない説明変数でモデルを作ることです.科学では『統計的問題解決入門』のコラム(p153)でも説明している「オッカムの剃刀」という考え方があります.より少ない仮定で説明できる理論のほうが信頼できるという基本姿勢です.モデリングにおいて,オッカムの剃刀で何をそぎ落とすかというと,推定されたパラメータです.剃刀に当たるのが,モデル効果の削除ボタン(ボタンのGUIになってませんが)です.
この意味で,重回帰分析に先駆けた単回帰分析も軽視できません.但し,OFAT(一因子実験)とは本質的に異なり,データは実験計画で取得することが前提です.この場合であれば,他の変数は層別に考慮することが可能です.共変量が考慮されていれば,単回帰分析でも実務においては十分価値があるように思います.なかなか現場が実験計画をやってくれないという皆様からの悩みを伺うに,1つ提案したいのが単回帰分析です.分析の交渉力とも関係あるので,この点を来週補足します.
それではまた.

コメント