
不正統計の報道で騒がしい昨今ですが,この言葉を聞くたびに「ちょっと違うのではないか」と思うのです.不正統計が何を指しているのかといえば,ご存知のように厚生労働省の毎月勤労統計の調査が正しく実施されていなかったという問題です.毎月勤労統計調査(いわゆる「マイキン」)では従業員500人以上の事業所はその全てが対象になっていますが,東京都内では3分の1しか調査していなかったとのことです.
母集団からサンプリングしてその平均値を母平均の推定値とするという行為そのものは統計学としては全く問題ありません.問題はサンプリングがランダムでなかったことです.日本全国の平均賃金を推定する場合,東京都内でのみ三分の一サンプリング(少しい変な言い方ですが,そのほかではサンプリングは全数)していたのであれば,母平均の推定値は真値よりも小さくなります.東京都には比較的賃金の高い事業所が集中しているからです.この報道を聞いたとき,サンプリングして東京都の平均賃金を推定した後,東京のサンプルサイズを3倍したのかと思っていましたが,そんな単純な処理すらしていなかったようです.どうしてそのままでいいと思ったのでしょうか.謎ですね.
とはいえ,この問題を不正統計と呼ぶのはやめていただきたい.確かにサンプリング手法は間違ってはいますが,統計手法が不正なわけではありません.おそらく不正統計というときの「統計」はデータの意味で用いていると思いますが,データ自身も捏造された不正なものではありません.この行為が問題なのは違法であるということです.毎月勤労統計調査は,それによって景気判断はもとより様々な政策が決定されるわけですから,国の基幹統計調査として統計法で定められているのです.ですから,今回の問題は不正統計ではなく不法統計と言って欲しいと思います.統計という言葉と不正という言葉が紐付けられてしまい,人のヒューリスティックな判断に影響をもたらすはずです.不正統計などという間違った言葉が蔓延るのは少なくとも統計教育にとって百害あって一利なしです.
統計には嘘はありません.「嘘には三つある.一つは嘘でもう一つは大嘘(真っ赤な嘘とも),そして三つ目は統計だ.」などというマーク・トゥエインの言葉が有名ですが,彼がこのイギリスの首相の言葉(諸説あります)を引用したのは,元々は「(私は)数字に惑わされる」という文脈でした.確かに数学には嘘はありませんが,数字には嘘があります.それと同じく,統計学には嘘はありませんが,統計データ(結果)には嘘はあります.嘘があるのはそこに人間がいるからで,嘘をつくのは人間なのです.それを統計のせいにするな,とわたしは言いたい.とはいえ,嘘をつくつもりがなくとも人間に間違いや勘違いは付きものです.そのための最低限の能力が統計リテラシーです.
例えば,マイキンでもその一部で全数検査が(本当に必要なのかは別にして)実施されているかもしれませんが,そもそも,日本の勤労者すべてを母集団とするならば,東京都のみ全数調査するのは正しいサンプリングなのでしょうか.精度を上げたいという意図は理解できますが,従業員が499人の事業所はおそらくサンプリング調査されているはずです.500人という区切りの根拠は明確ではありません.統計学の示すところによれば,所詮はサンプリングの結果に過ぎないのならば,推定値と合わせて信頼区間を提示すべきということです.
信頼区間を提示するには提示する側もされる側にもある程度の統計学の知識が必要です.この統計学の知識を読んだり書いたりする能力が統計リテラシーとも言えます.統計リテラシーを前提にしてデータの開示がなされるようになるべきですが,とある科学分野の論文を読んでいても,SDとSEを取り違えているようなものも目に付くくらいですから,役所に統計リテラシーを期待すべきではないかもしれません.
そもそもお上の統計の扱いには常々疑問を抱いています.e-Statが開設された時のゴタゴタは記憶に新しいところです.わたしもセミナー用のデータとしてe-Statをよく利用させていただいているのですが,そのほとんどがmessy dataです.JMPのマニュアルでは雑然データと訳されていますが,messyには散らばって汚らしいというニュアンスがあります.あまり触れたくない感じです.csvやxslで提供されているならまだしもPDFになっているデータがかなりあります.PDFというフォーマットは本来印刷用のものでデータ分析にかけることは想定されていません.
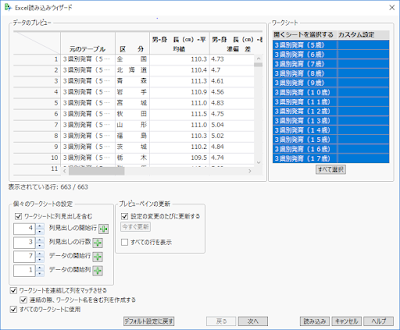
xslデータであっても,例えばこの学校保健統計調査のような見ることを前提としたデータが圧倒的です.年齢という重要な変数がシートに分割されてしまっています.これは困りました.おかげでわたしとしてはこれを他山の石としてセミナーの題材にできるのですが.さて,データはe-Statからダンロードできます.このmessy dataをJMPで分析するのはどうすれば良いでしょうか?例えば,身長と体重からBMIを算出してそれが年齢でどのように変化するのかを男女別に見たいとして,どうすればいいでしょうか.実はこの処理で一箇所つまずくところがあります.来週のブログで手順を合わせて回答しますので,お楽しみに.
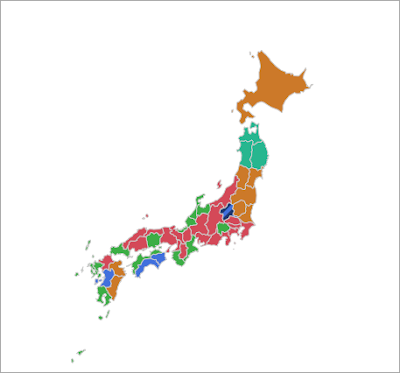
因みに結果の一部を示しておきます.データは「学校保健統計調査平成30年度(速報)」を使ってBMIのクラスタリング結果(性別,年齢を区別しない)を表示していますが,この分布を再現できますか?
それではまた.
コメント