統計学
統計学 イベルメクチンと信頼区間
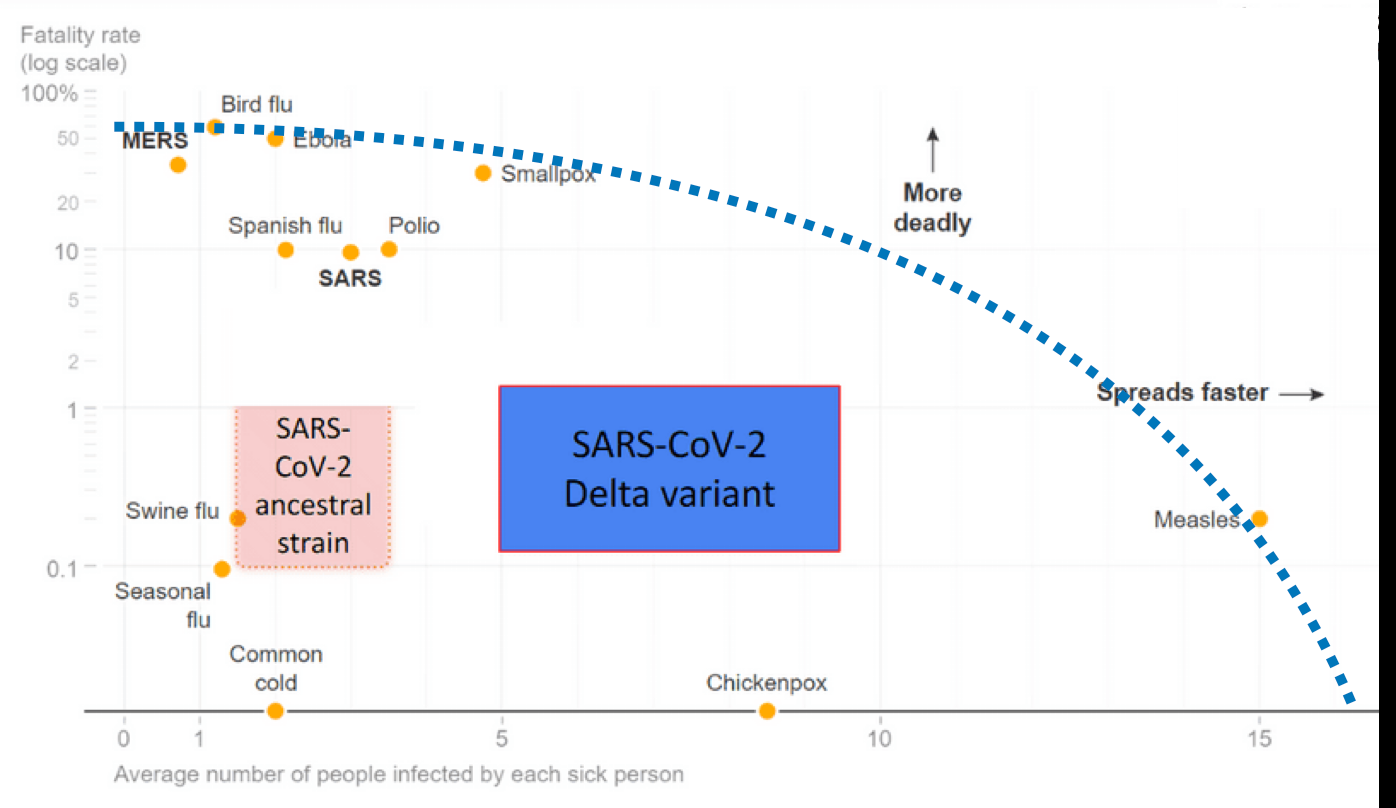
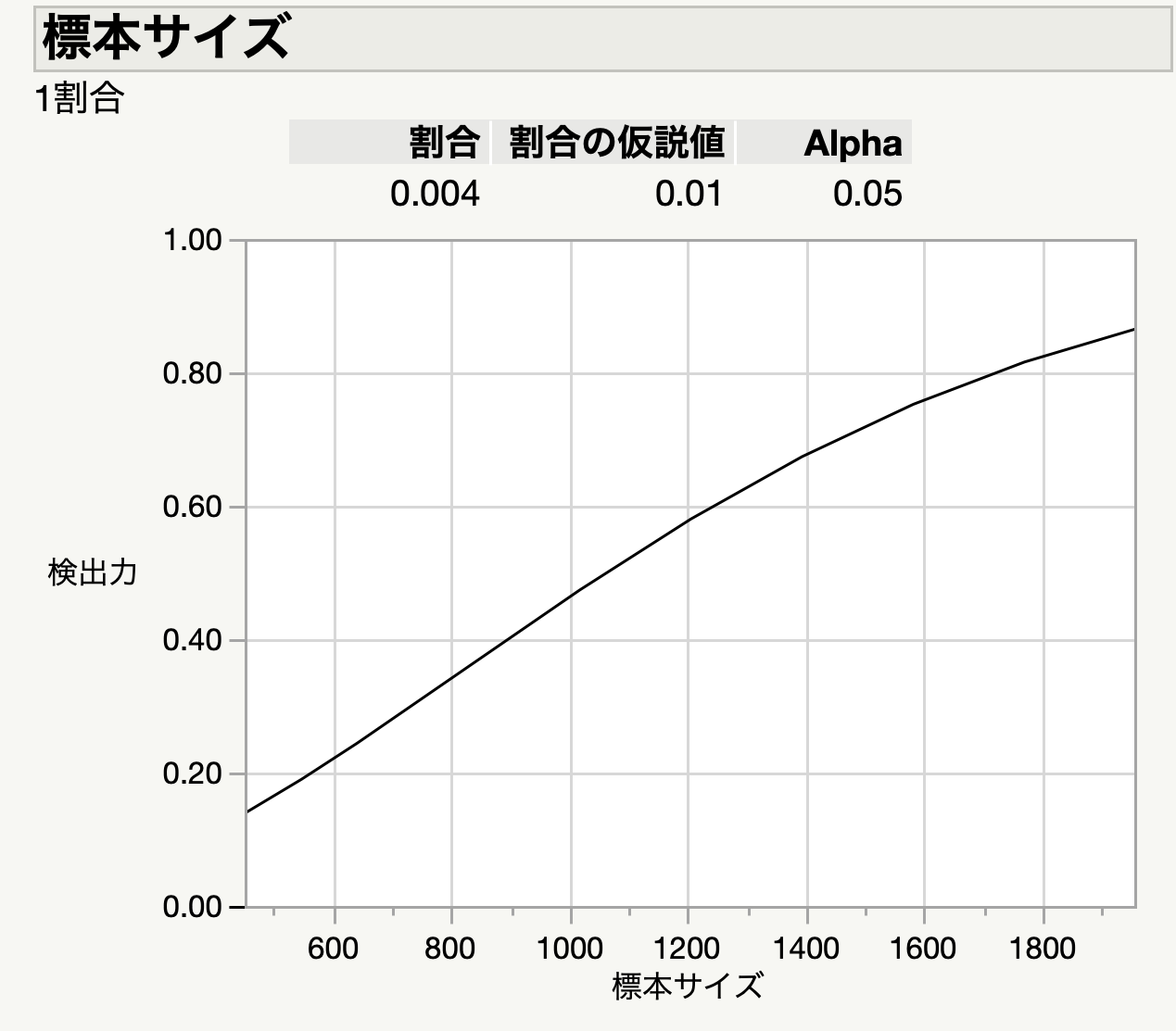
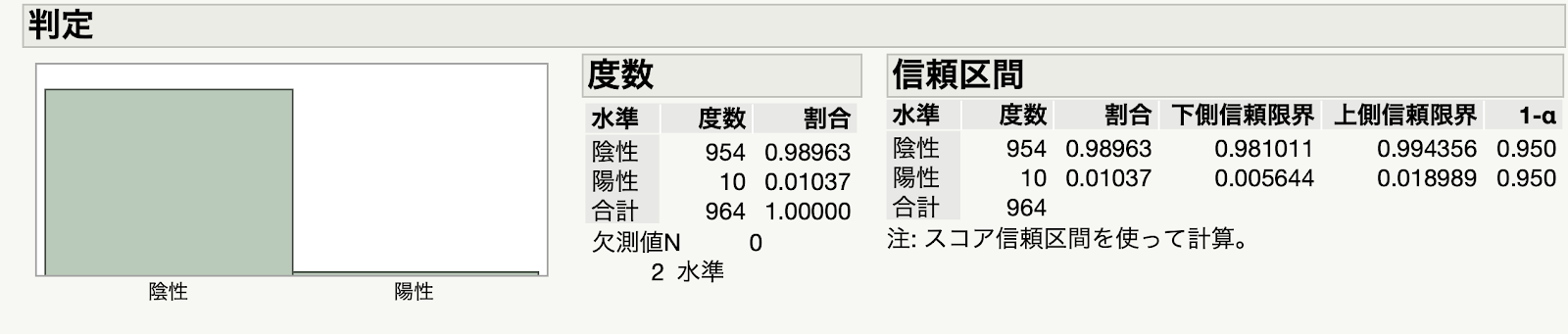
「イベルメクチン、新型コロナへの効果確認できず 国際チーム論文発表」という記事が出てました.イベルメクチンについては,データの改竄についてこのブログでも書いた記憶があります. このときから,既に証拠があやふやだと言われていたわけですけど,今回それがRCTによって証明されたことになります.new england journal of medicineに掲載された論文ということで,その影響力は水戸黄門の葵の御紋に匹敵します.何しろ,医学・生物分野での最高峰としてインパクト ファクター75です.この論文誌に掲載される学者はそれだけで大変なエリートです.世界四大医学雑誌と言われているのはこの雑誌に加え...