
先週は「不正統計」という言葉に待ったをかけました.不正統計ではなく不法統計と呼ぶべきであると.もっと正確には,不法なデータサンプリングであって,そこに統計の誤用が合わさったということです.この問題の根っこにはデータ軽視があるように思います.更には,正しく統計を使わなければいけないという決意も欠如しているように思います.それは,データは統計分析してこそ意味があるという認識がそもそも欠如しているからでしょう.先週予告したように,このことを実例を元に見ていきます.
サンプルデータは学校保健統計調査を選びました.このページの調査の結果の統計表一覧をクリックすると,そこに書いてあるようにe-Statに飛んでいきます.データはどれでも同様ですが,昨年の12月21日公開の最新の平成30年度(速報)から都道府県表をクリックして,表番号3の「都道府県別 身長・体重の平均値及び標準偏差」をダウンロードしてください.ファイル名は「h30_hoken_tokei_03.xlsx」となっているはずです. このエクセルファイルをどう思いますか?見ることを前提としたデータなので,JMPで分析しようにも一苦労です.決定的にダメなのは年齢という重要な変数がシートに分割されてしまっていることです.
このmessy dataを分析可能なデータ(tidy data)に変換するのが本日のお題です.この作業をData Tidyingと呼びます.tidy dataを整然データと訳されている方もいらっしゃいますが,自分的には整然ではどうもしっくりこないので「こぎれいなデータ」と呼んだりしています.整然とした部屋というニュアンスとこぎれいな部屋というニュアンスでは後者の方がtidyに近いからですが,学術用語としては適さないですね.素早く分析に着手できるという意味では「整頓」というのも近いです.
さて,以下に手順を示しますが,操作の順番は絶対ではありません.正解は一つではなく,以下は一つの例とご理解ください.
1. まずはエクセルファイルをExcel読み込みウィザードで開きます.前の設定が保存されているときは一度「デフォルト設定に戻す」を実行しておいたほうが間違いがありません.このファイルでは以下の設定にしてください.
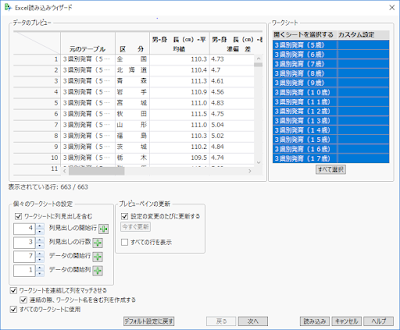
ここで「連結の際,ワークシート名を含む列を作成する」にチェックを入れることが重要です.この他の設定はデフォルトで構いませんので,直ちに「読み込み」を実行します.空白の行や列などのデータの欠測値を処理することも可能ですが,初めてのデータの場合はこの段階では放置しておくことをお勧めします.
2. JMPテーブルに変換できたら,最初にやるのは標準偏差の4列を削除します.(ここでは平均値のみを対象とします.)
3.「男-身長」「男-体重」「女-身長」「女-体重」の4列を積み重ねます.デフォルトでは,「ラベル」列と「データ」列ができます.以下の説明では列名はデフォルトのまま処理をすすめていきますが,適宜変更しても構いません.
4.「ラベル」列を選択して,「列>ユーティリティ>テキスト」を実行します.区切り文字は半角のハイフォン「-」です.全角が好きなお役所もここだけ半角なのが謎ですね.
5.「ラベル」列は削除します.「ラベル3」列もすべて「平均値」と入っていて分析には無意味なので削除します.(削除するのは後でもかまいません.)
6.「ラベル2」列には身長と体重というラベルがデータとして入っているのでこれを分割します.それには「列の分割」で「基準となる列」に「ラベル2」,「分割する列」に「データ」を割り当てます.このとき「残りの列はすべて保持」にチェックを入れるのを忘れないようにして下さい.
7.「ラベル1」を「性別」に名称変更して,「ラベル」列は削除しておきます.
8.区分には都道府県名が入っているのですが,このままではグラフビルダーで認識しないので,シェイプファイルが呼び出せません.なぜかというと,「北 海 道」のように意味のない空白が入っているためなので,これを削除します.それには「検索>検索」で「全角空白」を「」に検索置換します.この操作は二回繰り返さなければなりません.三文字の名称に合わせて二文字の名称が青(全角空白三文字)森のようになっているからです.このよう無駄な空白は誰が得するのか?お役所のデータを他山の石とすべきです.
9.いよいよ「元のテーブル」列に取り掛かります.例えば.「3県別発育(5歳)」となっている5を取り出すために区切り文字を(歳 とします.普段何気なくつけているワークシート名もJMPに呼び込むことを考えてつけるべきですね.
10.「元のテーブル2」には全角数字で年齢が入っていますので,列情報を名義尺度とし,列名も「年齢文字」と変更します.
11.回帰分析などのためには年齢を連続尺度にしておきたいところです.そのためには新規に連続尺度の列を作成して,そこに以下の計算式を入れます.ようするに全角の数字を半角の数字に置き換えるのです.
Num(
Substitute( :年齢文字,
“0”, “0”,
“1”, “1”,
“2”, “2”,
“3”, “3”,
“4”, “4”,
“5”, “5”,
“6”, “6”,
“7”, “7”,
“8”, “8”,
“9”, “9”
)
)
この計算式の関数NumもSubstituteも文字のところにあります.Substituteは下のほうです.
12.「区分」をデータフィルタにかけて,都道府県名以外の三つ(???と調査対象者(人)と全国)を選択して行を削除します.
13.列名は適当でかまいませんが,一般的「身 長(cm)」という全角半角入り混じった列名は「身長」としたいところです.一般的には列名には単位は入れないことをお勧めします.列名は変数名でもあるのでモデリングの際に見やすくなるからです.列の選択リストにも単位が表示されないので見やすいです.
14.どうしても単位をレポートに表示させたい場合は,列情報の列プロパティで単位を選び,所望の単位を入れてください.グラフなどには単位が表示されます.
この後,先週のグラフを作成するには,都道府県をクラスタリングしてから,「BMI」列を計算式で作成するだけですが,本日は所用があり続きは後日とさせてください.このグラフを見ると興味深いことが見えます.考察すべきこと色々あリますが,長くなったので本日はこれにて.
それではまた.

コメント