
一段と世の中が騒がしくなってきましたね.そんな中で菅,今日もブログだけは平常運転でいってみたいと思います.そうはいっても,特に書くこともないので,先週に引き続き,時事ネタを強引にJMPと紐付けてるという恒例のチャレンジをしてみます.先週は,横須賀市のコロナ抗体検査の結果の解釈に,統計的でもないのに「統計的に」という枕詞をつけるなと文句を言いました.そもそも「統計的に」という言葉をつける言説には,騙されるなという警告の意味があると解釈しています.さて,最近は,様々な自治体で同じ試みが実施されているようです.数日前のニュースでは宇都宮市でも無症状者を対象に抗体検査を実施したようです.
こちらがその記事です.これによれば,742人中3人の陽性者が出たとのことです.この場合も,2290人を無作為抽出してはいるものの,応じたのは742人ですからそのうちの1/3です.やはり,結果としては無作為ではなく,なんらかのバイアスがかかってしまっていると疑えますが,そのことは今日は脇に置いておきます.引っかかったのは,記事のこの部分です.
以下引用
この時点の感染率は0.40%だが、統計学的に精度の高い数字に補正すると1.23%になるとしている。6月1日時点の同市人口(51万8610人)に換算すると感染者数は推定6378人。「第1波」とされる時期に市が把握していた陽性者23人の277倍に当たるという。
引用ここまで
「統計学的に精度の高い数字に補正すると」という部分に注目してください.これどういう意味でしょうか.そこで先週と同じように,「一変量の分布」で信頼区間を求めてみます.(普段は英語のUIを使うことが多く,裏で分析途中のテーブルが大量に開いている状態で,日本語UIに切り替えるのが面倒なのでそのままですいません.)
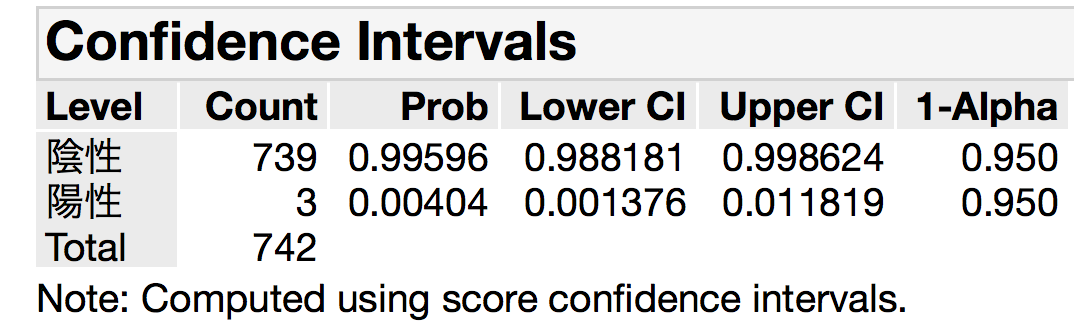
上限は1.18%ですから,精度の高いという1.23%と異なってます.この信頼区間はそこにも書いてあるように,スコア信頼区間,日本ではWilsonのスコア信頼区間と呼ばれる二項分布から計算される信頼区間です.
おそらく,記事にある「統計学的に精度の高い数字」は信頼区間とは関係ないところからきているのか,それとも異なる統計量なのか?気になったので,他にもある信頼区間を求めてみることにしました.残念ながら,JMPでは「一変量の分布」プラットフォームで出力される信頼区間は限定的なので,Pythonを使ってみます.といってもプログラムを書く必要はなく,
from statsmodels.stats.proportion import proportion_confint
で簡単に実装できます.
proportion_confint(count, nobs, alpha=0.05, method=’normal’)の引数のmethodのパラメータはデフォルトではいわゆるWald法による信頼区間を与える「normal」ですが,その他に次の種類が用意されています.
- normal : asymptotic normal approximation
- agresti_coull : Agresti-Coull interval
- beta : Clopper-Pearson interval based on Beta distribution
- wilson : Wilson Score interval
- jeffreys : Jeffreys Bayesian Interval
- binom_test : experimental, inversion of binom_test
検証の結果から言いますと,おそらく1.23%という上限値はAgresti-Coullの信頼区間ではないかと予想できました.Agresti-Coullの信頼区間はWaldの信頼区間を修正したものですけど,サンプルサイズが大きいときは大差ないと認識していました.興味ある方は,どうぞガチの統計論文ですが,こちらをお読みください. 確かに値は異なりますが,統計学的に精度が高いというのは,全くのミスリーディングですね.統計学学的により精度の高い信頼区間と言うことはできるかもしれませんが,そもそも95%の信頼区間の上限値ですから,1.23%という値に意味を持たせてはいけません.
因みに,日本では,Agresti-Coullと英語表記のまま書かれることが多いのですが,Agrestiの方はカテゴリカルデータ分析の大家であるフロリダ大学のアラン・アグレスティ先生で,Coullの方は先生のもとで当時Dr.だった現在はハーバード大学で生物統計学の教授のブレント・クール先生です.Wikiなんかではコウルと訳されていますし,有名なイギリスのCoulle Quartet は日本ではカウル弦楽四重奏団と呼んでいたりと混乱していますが,少なくとも人名ではクールと読むのが普通です.ですから,アグレスティ-コール信頼区間と呼ぶべきだと思うのですが...
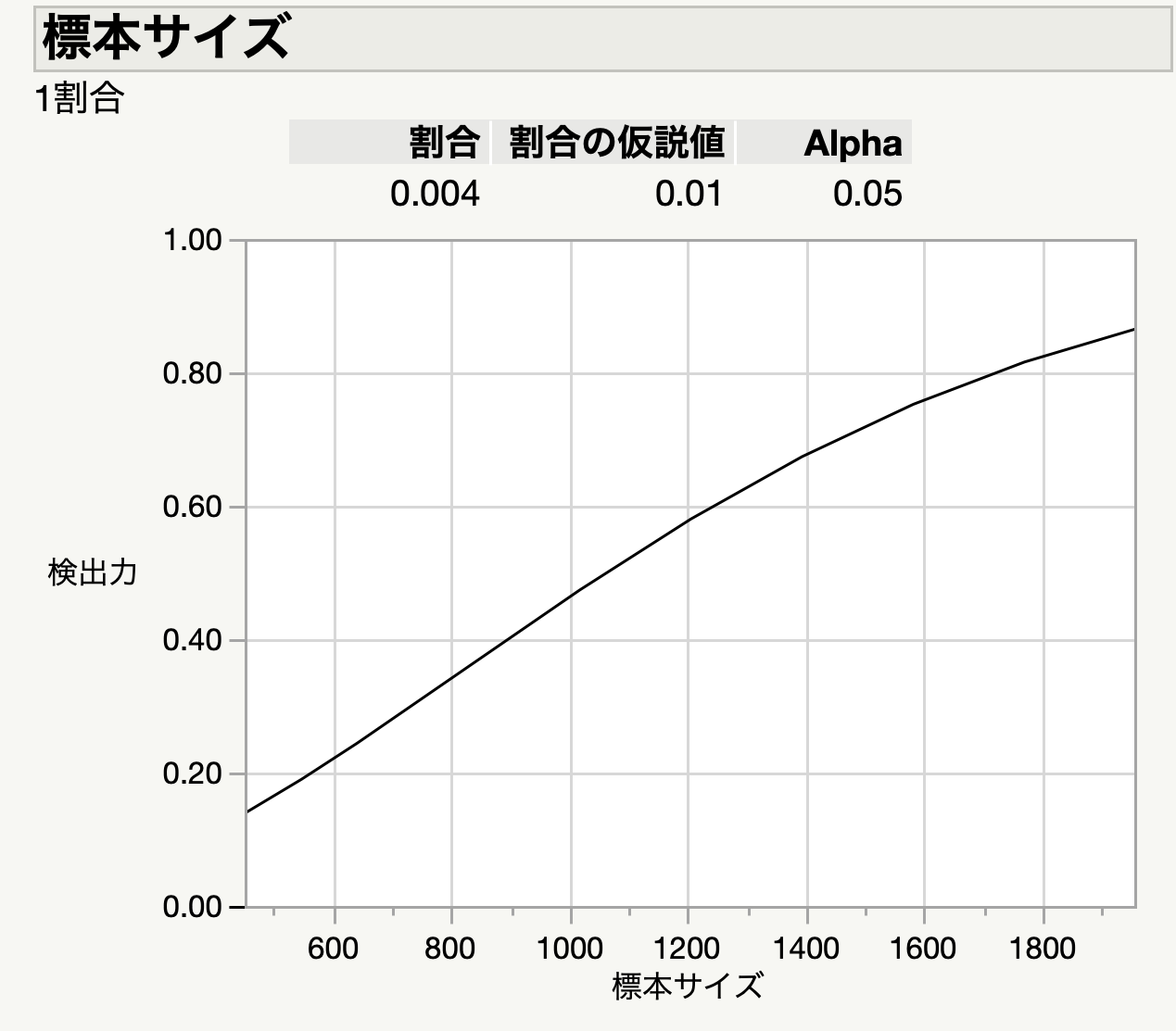
閑話休題.JMPではAgresti-Coull信頼区間は,私の知る限りでは直接出力できませんが,Agresti-Coull検定として,実験計画メニューの「計画の診断>標本サイズ/検出力」で『1標本割合』を選択すると登場します.デフォルトでは「方法」が『近似Agresti-Coull検定の正確検出力計算』となっているはずです.この手法で,今回の宇都宮市の結果を評価してみます.少なくとも0.4%と1%の違いが検出できなければ結論が無意味ですから,割合の仮説値を0.01として,検出力と標本サイズの関係を示したのが冒頭に示したグラフです.(結局,日本語UIに変更しました.)これによれば,0.8を得るための標本サイズは1700人程度でしょうか.全然少ないですね.逆に742人では検出力は0.25程度です.統計的に信頼できる結果ではないと言うことです.お金と時間の無駄だったとまでは言いませんが,やるのであれば政府主導でもう少し大規模に実施することが必要かと思います.個人的には,学校などである程度強制的に検査できなければバイアスの影響が気にはなるところです.
それでは,本日はこれにて失礼します.
コメント