
ここのところ冷え込んできましたね.先週もインフルエンザの話をしたばかりですが,今年は例年より流行期入りが早いということです.全国に約5000ある医療機関からのインフルエンザ患者の報告数が定点モニタリングされていて,その平均が1を超えたときが流行期入りの目安です.厚生労働省によれば,都道府県ごとに集計すると,11月17日時点で,31都道県が流行期入りしています.こうなると加速度的に患者数が増えていきます.今年はラグビーのワールドカップが開催されたりして,訪日外国人が多かったことが例年よりも早い流行の原因とみられています.
インフルエンザ過去10年間との比較グラフ(11/29更新)を見ると確かに今年は35週あたりから患者数が増えているようです.黄色い線なので目立たないのですが2009年に新型インフルエンザのパンデミックがあったことをすっかり忘れてました.それにしても,エクセルでグラフ描くのやめてもらいたいですね.とにかく見にくいし,そもそも年単位でグラフを書いているのもセンスを疑います.30週くらいを起点に描いて頂いた方が見やすいです.可視化のグラフは見てもらう立場に立って描くという基本ができてないです.
因みに,この定点のインフルエンザ報告数nをもとに全国のインフルエンザ患者数が推計されているのですが,昨シーズンから従来の推計方法が変更されています.定点の医療施設数を5000とすると,従来は「n/5000×全医療施設の施設数」で推計されていたのですが,「n/定点医療施設の外来患者延数 ×全医療施設の外来患者延数」になりました.5000ある定点観測の施設はおそらく大きい病院が多いでしょうから,患者の集中を補正するという当たり前の補正です.このため,以前の結果と比較するには,従来の推計値に0.66という係数をかける必要があります.なんで今頃という感がありますが,お役人の統計リテラシーは例の毎月勤労統計でもよくわかったように,データを扱う側が注意しなければなりません.

もしかしたら昨年のブログでも引用したかもしれませんが,疑惑のグラフはここで見ることができます.確かに,一般消費者向けの視覚化のグラフとしては色々問題ありそうです.例えば,1ページ目のグラフは,よく見ると縦軸が対数です.そのことは間違いではないにしても,比較対象としてビタミンCや乳酸菌を選択して,それをグラフにしたがために対数軸にせざるを得なかったのかもしれませんが,実験センスがないです.そうする必要があったのかも疑問です.
この資料の他のグラフにも,ネットでは色々と問題点が指摘されていますが,私は最後の10ページ目のグラフを見て,おやっと思いました,それというのも,このグラフの引用元を原著を読んでいるので,このようなグラフは掲載されていることを知っているからです.さて,このグラフはどうして出てきたのかというと,原著ではインフルエンザのA型とB型とが区別されたデータも載っているので,それをもとにして描かれたものと思われます.インフルエンザの予防効果ですから,区別しないで比較した方が素直なはずです.原著ではカイ二乗検定で有意性が示されていますが,インフルエンザの型で区別していません.
カイ二乗検定 はJMPでは分割表分析から実施できます.そのためには処置変数と結果変数を「二変量の関係」のそれぞれ『説明変数』と『目的変数』とに設定してレポートを出力します.赤三角の「検定」でカイ二乗検定の結果が得られるわけですが,この場合のような2×2分割表ではデフォルトの「尤度比」と「Pearson」という二種類のp値に加えて「Fisherの正確検定」の「片側検定」「両側検定」のp値も表示されます.結果から言うと,インフルエンザの型を区別しないで比較した場合,いずれのp値でも0.05以下となります.

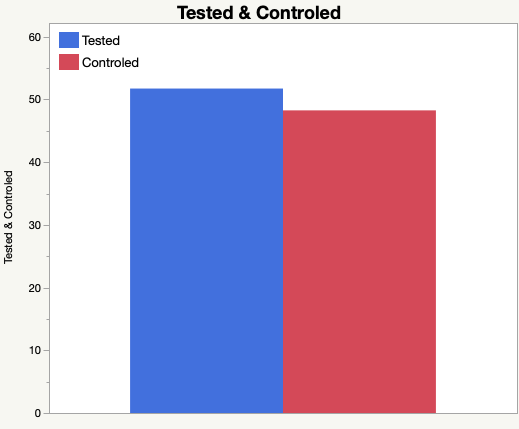
この結果から,紅茶うがいの有無のグループ間でのインフルエンザ罹患は均質ではないと解釈できます.この状況をグラフにしたのが冒頭の図です.
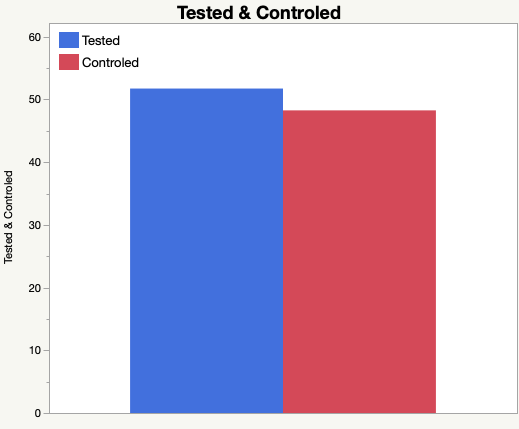
ところが,三井農林の資料にあるグラフのようにインフルエンザの型別に検定をかけるとこのように帰無仮説が棄却できないのです.こちらはA型の結果です.(B型の方は実施してません.)

確かに罹患総数で比較すると5%有意なので原著論文には間違いはありません.ところが,インフルエンザの型で区別すると有意性がなくなってしまうのです.おそらく,このために原著では型ごとにデータを取りながらも,検定はインフルエンザ罹患総数で実施したのでしょう.この事情を無視して作成した三井農林の資料に掲載されたグラフは間違いではないでしょうか.グラフの見た目だけでは型ごとに比較した方が差があるように見えることも関係しているかもしれません.
上記は10分ほどで分析したので間違いがあるかもしれません.みなさんもJMPで検定してみてください.間違いあればご指摘を.
それではまた.


コメント