
イベルメクチンのことを少し前に書いたけど,ここにきて衝撃的なニュースが.なんと,新型コロナ感染症に対するイベルメクチンの薬効をサポートする重要論文が取り下げられたのです.既に,薬効を否定する論文も発表されています.こうなると北里研究所とMeiji Seikaファルマが共同でイベルメクチンを用いた新型コロナ治療薬を創製するなんてきいてたけど,その影響は大きそうですね.
この記事を読むと,その理由がデータの信頼性に問題ありということで,しかも一部には捏造も含まれているとか.今まで論文はちゃんとは読んでいなかったので,これを機会に読んでみました.それというのも,このネタは統計リテラシーのセミナーで使っているので,きちんと検証しておく必要があるのです.
セミナーでは,タイトルだけからでもRCT実施の可能性が高いと判断すれば読むに足りる価値がある,などと説明しています.確かにRCTを実施した論文であることには間違い無いのですが,そのデータに信頼性がないということまでは見破れませんでした.出典を確認してその雑誌の信頼性を問うことも強調しているので,やはりピアレビュー通ってなければ信頼できないのかもしれません.
それで,論文に目を通してみたところ,すぐに気がついたのが,対照群がすべてICUのオブザーバーであったことです.形式だけRCTだけど実際にはRCTにはなっていなかったということです.他にもバイアスがかかっているので,これはRCTのまずい例として良い練習問題に使えそうです.
先ほどの記事によれば,データの捏造,どうやら単純なコピペもあるようなので,それをJMPで探ってみました.使ったのは「パターンを調べる」です.このプラットフォームはJMP15から実装されたんですけど,今一つ使い道がはっきりしなかった.セミナーでは,センサーデータを使ってデモしてますが,あるとき,これはフォレンジックに使えるのではと思いついた.
いわゆるデジタル・フォレンジックは法廷での証拠となり得るデータの分析のことですが,もっと広くデータの捏造・改竄の検出技術くらいに思ってください.ということで,実際のデータで試してみました.
「パターンを調べる」は連続尺度の変数のみ対象とするので,ほとんどの変数は分析から外れてしまいます.それでも残った連続尺度の変数で試すと,1列ごとのパターンですぐにコピペと思われる箇所を見つけました.こちらがその結果です.
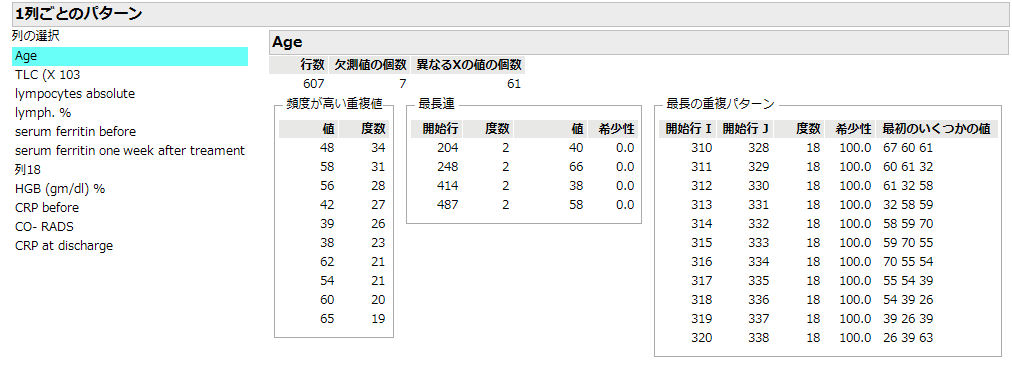
そしてこちらが該当箇所の一つです.対象にしたのは,「Age」だけですが,他の列も310行目から327行目と328行目と345行目とが見事一致してます.単純なテーブル操作のミスとは思えないのは,「名前」だけは異なっているから.しかも多くでイニシャルが一文字違いなので,おそらく手打ちしたんだろうなと思う.筆者は何を思って,馬鹿げたしかも幼稚なデータ操作を行なっていたんだろう.
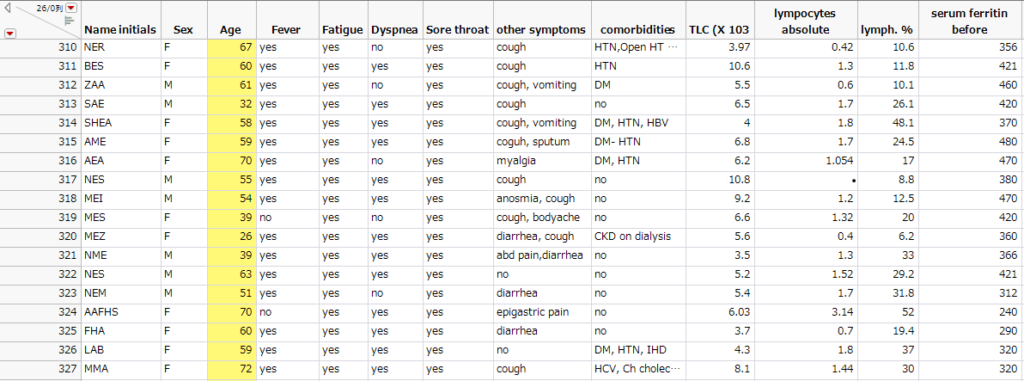
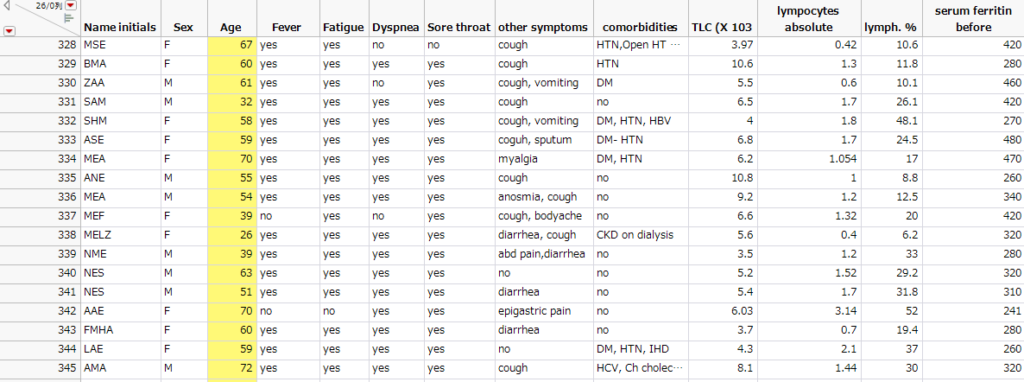
統計は嘘をつかない,嘘をつくのは人間だ,と言っていますが,正にその良いしかし残念な例となってしまいました.このデータを分析している過程で「パターンを調べる」の他の機能が色々とわかってきたので,それはまた今度紹介します.
それでは,また.
コメント