
冒頭から如何わしいタイトルで恐縮です.血液型と性格の関係がどうこうという話ではないのでご容赦ください.様々なデマ情報も飛び交っている昨今では,それら情報の裏を取るという必要があり,ここのところ色々な文献を読みまくっています.311の当時を思い出す状況です.あのときも随分と勉強しました.このときの蓄えがなければ,おそらく『JMPではじめる統計的問題解決入門』は執筆していなかったかもしれません.p46の「ネ申エクセルの話」というコラムにも当時のことを書いていますけど,あの頃色々と勉強したことが集積していって,それが書籍として実態化したように思います.
さて,ここのところコロナをネタにしていて,先週は気がひけるとまで書いたもののの,今週も懲りずにコロナネタです.データ分析の上達には自分に興味のある題材をとるのが一番なので,3月18日の中央日報日本語版の記事から本日の題材をとります.「中国感染者2000人の血液型見るとA型がO型に比べて感染に脆弱」この原著論文はmedRxivで簡単に探せました.著者はJiao Zhaoその他です.Relationship between the ABO Blood Group and the COVID-19 Susceptibility
まずこの論文はプレプレスで査読前ですから,その点ご注意ください.内容は,題名が示すように,血液型とコロナウィルス感染症の罹患との関連を研究したものです.結論から言うと,A型が掛かりやすくO型が掛かりにくいとのことです.血液型性格診断は,ニセ科学の代名詞のように言われているのですが,科学的には一部の疾病とは関連性が報告されています.このへんの説明はこの記事にも書かれています.手洗いの習慣が感染と関係あるという前提のもと,一般的に言われているA型とO型の性格が仮に正しいとすれば,A型の方が感染しにくいはずです.感染しやすいという性質が遺伝的,後天的に性格を形成していくという可能性もあるので,因果関係は何とも言えませんけど.因みに,米国の黒人は確か80%以上がA型だったと記憶しているので,この研究が正しければ人種間で感染率に有意差があるはずです.とはいえ,血液型と感染しやすさには多少の関連性はあるのかもしれませんが,おそらくその他の要因に埋もれてしまってしまっていると推察します.統計学的には有意差があっても,医学的,社会学的にそれが意味があるとは限りません.いずれにせよ,血液型性格判断は遊びを超えると害悪しかないのでご注意を.
心理学,医学的な解釈はさておいて,このブログでは初心者向けにこの原著論文の統計分析をJMPでフォローしてみます.先ずはデータテーブルを作成してください.「BT」(Blood Type)列と「Infected」列,それに度数を入れる「f」列を新規作成してください.最初の2つの変数は名義尺度で,カテゴリーはそれぞれ(A,B,AB,O)と(Yes,No)とでもしときます.その上で,それぞれの人数をテーブルに手入力します.「Infected」が「No」にはControlled caseを入れることになります.ついでに検定で必要になるので,「再コード化」でA型以外を非A型,O型以外を非O型とした列「BT2」「BT3」も新規に作成しておきます.このようになりましたでしょうか.

原著論文では,両側カイ二乗検定で統計的な有意性を示しています.統計処置にSPSSとSTATAを使ったと書いてありますが,これをJMPでフォローするにはどうすればよいでしょうか?考えてみてください.
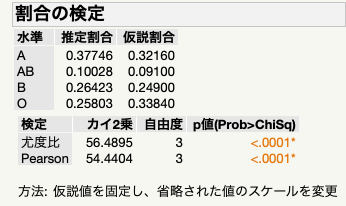
「一変量の分布」から「割合の検定」を実施するのが1つの手です.この場合,Controlled caseから算出した「仮説割合」を記入する必要があります.『完了』をクリックすれば,レポートの「Pearson」のところに通常のカイ二乗値を使った結果が出力されます.結果は冒頭に示した通りです.とはいえ,これでは原著論文の「オッズ比」が出力されません.そこで「二変量の関係」を使います.
最初にA型の人が感染しやすいことを検証するために,先ほど「再コード化」した「BT2」列を使います.『Y』に「Infected」,『X』に「BT2」,『度数』に「f」を割り当てて『OK』です.このブログで何回も出てきた「モザイク図」が出力され,このような2×2のクロス表であれば,デフォルトでレポートには「Fisherの正確検定」も出力されます.


2×2以外に「Fisherの正確検定」を拡張する手法があるのですが,これはJMP Proには実装されていたように思います.(手元にJMP Proがないので記憶が定かでなく,もしかしたら間違いかもしれません.)このため,ここではB,AB,O,を非Aとまとめたのです.とにかく,このレポートに書いてある通り,<0.001で有意性ありということは確認できました.
2×2であれば,「オッズ比」も赤三角から出力できます.ですが,出力値は0.781849と論文に掲載されている値と違います.これはどうしてでしょうか?そもそもオッズ比とは,ある疾病の罹患を二群(実験群と対照群)で比較する際の,医療統計分野でよく使われる指標です.オッズ比が1ならば,罹患のしやすさは両群で同じで,1より大きければ実験群は罹患しやすく,1より小さいときは,逆に罹患しにくいことを意味します.
例えば,この論文ではコロナウィルス感染症に関する危険因子として血液型がA型であることのリスクがどれだけ高いかを評価したいのです.罹患群1775名中でA型は670名であり,一方,健常群(制御群)は3694名で,そのうちA型は1188名でした.このときのオッズ比は次のようになります.
感染者A型/感染者非A型 / 健常者A型/健常者非A型
=670/1105 / 1188/2506
=1.279
このことは,コロナウィルス感染症の罹患者ではA型が出現する確率は健常者よりも1.279倍大きい,すなわちA型の人は感染するリスクが1.279倍高いということです.
さて,JMPは上記の定義は計算式として記述されているだけです.仮説を踏まえて,どの数値が実験群でリスク因子は何か,ということを理解してテーブルに入力するのは私たちの仕事です.JMPでは,名義尺度の変数の値はアスキーコード順に並ぶのがデフォルトです.このため,上記ではオッズ比の逆数が出力されていたわけです.正しい解釈のためには,「BT2」の「列情報」で『列プロパティ』をプルダウンして「値の順序」を選び,出現したパネルで「非A」を選択し『上へ移動』してから『OK』する必要があります.その上で赤三角から「やり直し>分析のやり直し」をどうぞ.

これでオッズ比が95%信頼区間とともに表示できました.この結果は原著論文とも一致しています.O型が感染しにくいという検定も「BT3」列を使って同様に実施できるので確認してみてください.
今日はここまで.それではまた.

コメント