
外出自粛要請の週末,いかがお過ごしでしょうか.自転車で遠乗りするには良い季節にはなってきましたが,ここ当面は控えて家に籠ることにしました.人と接触するわけではありませんが,事故でも起こせば医療リソースに負担をかけることになります.現時点では,最も避けるべき行動と判断しました.こんなときは,自宅でもできるデータ分析も趣味で良かったと思っています.最近では色々と不安な情報に振り回される毎日ですが,そんな中でもデータ分析の力を発揮して,少なくとも自分だけは正しい意思決定をしていこうと,そう考えています.皆様も,その結果をご家族や同僚など身近な人と共有して,できるだけ易しく説明してみることをお勧めします.その過程で,拙著でも強調した「視覚化」と「可視化」の違いが体感できるはずです.
本日の記事も,基本的にJMP初心者を対象としますが,上級者の皆様とはグラフの背景を一緒に楽しんでまいりましょう.趣味のデータ分析はネタ探しから始めます.趣味ともなると電車内の広告を見てもネタになりますが,昨今ではとにかくネタには事欠きません.メディアリテラシーが身についてくると,データソースが定かでなければ,そもそも読むに値しない情報ということがわかってきますが,最近はソースが明確になっているものも多いようです.そこで,先ずは信頼できるメディアに掲載されているグラフを自分で描いてみることをお勧めします.例えば,最近こんな記事を目にしました.
新型コロナの外出自粛要請を最も無視しているのは名古屋、アップルの移動データ解析サイトから判明
データの出典もリンクされているので,それだけは良心的な記事と思います.
このグラフをJMPで描いてみると,確かに名古屋のMobilityは他の都市よりも大きいようです.果たして名古屋では自粛要請が無視されているのでしょうか.このことを,JMPで確認してみます.データはAppleの特設サイトMobility Trends ReportsからCSVをダウンロードします.ここでは昨日ダウンロードしたデータを使いますが,このデータは毎日更新されているので皆さんは最新のデータをお使いください.それでは以下にグラフ作成の手順を書いていきますが,その前にどうすればいいのかを考えてみてください.
1.ほとんどの場合,CSVは右クリックでJMPから開くのが一番早いです.特にこのような英語のデータは問題がないことが多いです.日本語のデータでは,文字化けするものもたまにありますが,その場合は,CSVを一度エクセルで開いて保存することで回避できることがあります.
2.データがどのようにレイアウトされているかを眺めるのが次のステップです.それぞれの日付が列名になっていることがポイントですね.横軸を日付に取ってグラフを描くには,列として積み重ねたいところです.この段階で「データフィルタ」して日本の各都市のデータだけ抜き出してもいいのですが,せっかく世界各地データが記載されているので,ここでフィルタリングしてしまうのはもったいない.そこで,先にテーブルメニューから「列の積み重ね」を実施します.「2020-01-13」列以降のすべての列を『積み重ねる列』に指定して『OK』です.積み重ねない列は『すべて保持』になっていることは確認してください.
3.「データ」列にはすべての国名や都市名ののMobilityが繋がっているので,これを分割するのですが,このデータでは注意が必要です.おそらくその地域の事情によるのだと思うのですが「taransportation_type」のうち「transit」がない地域があるのです.このデータでは,「region」の最初の「Albania」がそうです.「列の分割」は単純に列の先頭のパターンを見て,それを分割基準に採用するので,このままでは「transit」のデータが抜け落ちてしまいます.このような場合,先頭にダミーデータを付加したり,一度データを「taransportation_type」のそれぞれでフィルタリングして作成したテーブルを『結合(Join)』する手があります.「列の分割」で『基準となる列』に「region」の他に「transportation_type」を追加してもいいです.あるいは,同じ地域では「taransportation_type」間の相関が大きいので平均を採用してもいいかもしれませんし,どれか1つの「taransportation_type」を代表にとって考察してもいいでしょう.今の場合,特に日本では交通機関の利用状況に関心があるので,「transit」だけを抜き出して比較することにします.
4.ということで「データフィルタ」で「transit」を選択して,赤三角から「サブセットの表示」して,このサブセットを「列の分割」します.設定が難しいとよく質問受けるのですが,何を分割したいのかを考えれば大丈夫です.今の場合Mobolityを国や都市毎に分割していくので,「データ」を『基準となる列』に,「region」を『分割する列』に割り当てて『OK』します.このとき「積み重ね」と違って「残りの列」は『すべて除去』がデフォルトになっていることに注意してください.『選択』にチェックを入れて,リストから「ラベル」を選択して,『選択されている列をすべて保持』をクリックしてから『OK』します.こうしてすべてのグラフ作成の元となるテーブルができたので,これを保存しておきます.
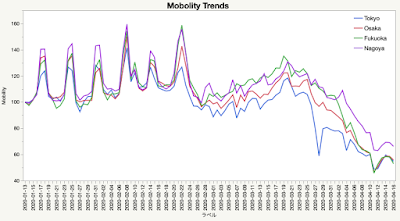
5.それでは,日本の各都市のMobilityを比較してみます.「グラフビルダー 」でXゾーンに「ラベル」をドロップしてください.ここではデフォルトのままでいきますが,適宜変数名は変更して構いません.Yゾーンにはリストから日本の各都市を選択すればいいのですが,92列もあるのでリストの赤三角から「フィルタの表示」をするといいでしょう.この検索ボックスは文字の並びがキーとなるので「to」と打つと「Tokyo」だけでなく「Boston」なども一緒に検索されるので注意してください.「Tokyo」をYゾーンにドロップしたら,それ以外の都市を選択してYゾーンのグラフ内側の六角形の追加ゾーンにドロップしていきます.仕上げに『折れ線』ボタンをクリックすれば,冒頭に掲げたグラフになります.このグラフでは,X軸の「軸ラベル」を調整して文字が見えるように表示していますが,ラベルが間引かれていることには注意してください.
確かに名古屋は,他と比べてMobilityが大きいようですが,そもそも「transit」が何を計測しているのか今一つ不明なので,何かを結論するのは危険です.例えば,東京と福岡では交通状況も違いますよね.東京では通勤に車を使うのはごく一部の人に限られていますし,バスでの移動はDriveになるのか,等々.いろいろな疑問は後日調べることにしましょうか.それよりも,自分で描いてみれば,このMobilityは1月13日を100%とした相対的な数値であることに気づくはずです.まだこの時期はコロナの気配は感じつつも自らの行動を制限するような状況ではなかったと思います.最初の日本での感染者が1月16日で,10人を超えたのが1月30日です.そこで,その翌日の1月31日を基準にしてこのグラフを描き直してみます.
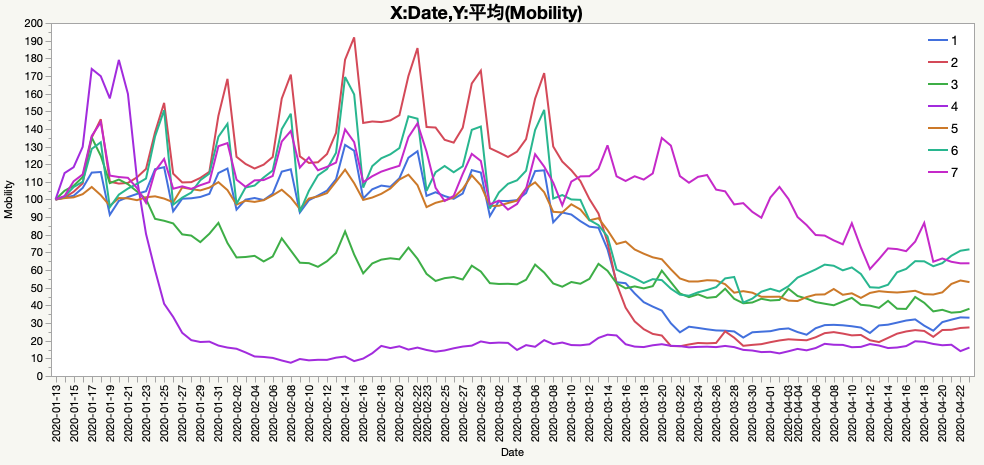
それには「東京」列を作成して,計算式 (:Tokyo / 128.14) * 100を入れます.以下同様にして作成したのがこの図です.

随分印象が違いますよね.もちろん,どちらのグラフも基準が異なるだけで間違いではありません.重要なことは基準は意識的に選択できるということです.ですから,ここにデータ可視化の落とし穴があるのです.何よりも注意したいのは,私たちが意識せずに基準を選んでいる場合です.データを可視化したつもりで,正しい情報が得られないとだけでなく,こうして得られた間違った情報からの呪縛はとても強いので,この後に様々な弊害をもたらします.メディアの場合,意図的に間違ったグラフを描いて視聴者を誘導するというよりも,自分で自分に騙されて大騒ぎしているという場合もあります.更には,データの視覚化では,このように意図的に「名古屋は自粛無視している」という説得材料とすることも可能だということにも注意が必要です.
多いこみで失敗することは誰にもあると思います.私の経験で言えば,特許を書いていて,最後の最後までロジックが破綻していることに気付かず,それまで明細書に費やした数日間がすべて無駄になったことも一回ではありません.最初の思いつきにとらわれることの怖さ,それを客観的にデータを見ることとで学べたと思っています.
来週はこのデータを使って,別の分析をしてみようと考えています.
それでは,また来週.
日本や他の国はもちろんですが,ニューヨークの古き友人たちが早く安心して暮らせるようになりますように.
コメント