
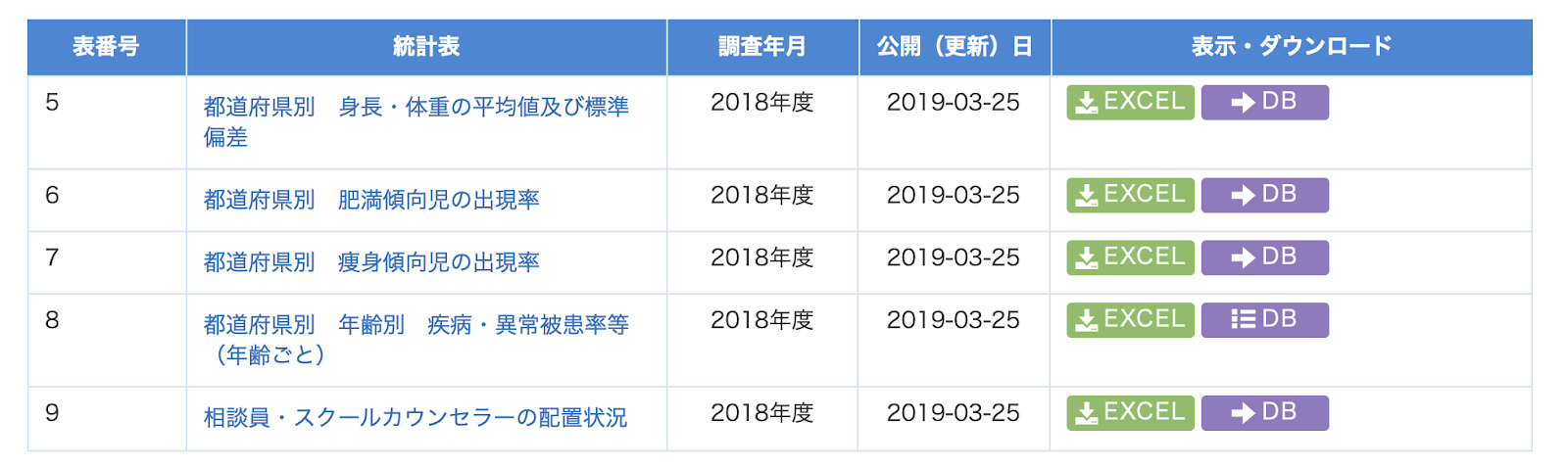
リリースしてまだ日も浅いのですけれど,オーム社に読者から問い合わせがありました.そこで,本日は『JMPではじめるデータサイエンス』の訂正というか補足についてお知らせします.p72の下から始まる練習2で「学校保健調査」のデータをダウンロードするのですが,そこで説明しているファイル名が実際と異なっているというご指摘でした.早速確認したところ,練習に使うファイルのファイル名は確かに現在のe-Statでは「h30_hoken_toukei_05.xlsx」となっていました.書籍に掲載したファイル名と異なっています.下の図の一番上(表番号5)のEXCELファイルが該当するファイルです.
記録によれば,私がこのファイルを最初にダウンロードしたのは今年の1月28日です.当時はこのファイルは「h30_hoken_tokei_03.xlsx」という名前でした.今となっては証拠はないのですが,ファイル名の変更はしていないので間違いありません.不思議に思い,e-Statの更新日を見ると3月25日になっています.おそらく,この日にファイル名が修正されたのではないでしょうか.ちょうど本書のこの部分を執筆中だったのでよく覚えているのですが,今年の2月9日のブログでもこのファイルを扱っていて,そこでは以下のように書いています.
表番号3の「都道府県別 身長・体重の平均値及び標準偏差」をダウンロードしてください.ファイル名は「h30_hoken_tokei_03.xlsx」となっているはずです.
よく見るとtokeiがtoukeiに修正されたりしているので,おそらく,あちら側でファイル名を付け替えた可能性があります.念のため,インターネット アーカイブもチェックしてみたのですが,残念ながらつい最近(12月8日)のアーカイブしか残っていませんでした.校正時点でもJMP15対応のチェック時にもファイルそのものは確認したのですが,e-Statまで行ってファイル名も確認すべきでした.
このe-Statですが,実はAPIが実装されていて,XMLで出力できるのをご存知でしたか?更に,APIの仕様書によれば
<親要素名>
<子要素名1>文字型値</子要素名1>
<子要素名2>数値</子要素名2>
</親要素名>
このようなXMLを次のJSONやJSONP(JSON with padding)フォーマットに変換することも可能なようです.
“親要素名”:{
“子要素名1”:”文字型値”,
“子要素名2”:数値
}
JSONのメリットは何と言ってもjavascriptのフォーマットにのっとっているため扱いやすく視認性に優れていることです.利用するにはアプリケーションIDを取る必要がありますが,JMPでもJMP14からJSONが読み込めるようになったので,簡単なJSLを書いてJSON経由でデータをJMPに読み込むことができます.本書でも当初JSLを使ってCSVでデータを取り込むことも考えたのですが,初心者向けの本なので見送りました.自分の仕事ではe-Statを利用することは滅多にないので優先順位は落としてますが,いつかe-Stat接続のJSLを作ってみたい思っています.
このような状況ですので,読者の皆様にはお手数をおかけしますが,ひとまずオーム社からサポートファイルをダウンドードして,それを使って実習していただけないでしょうか.JMPの本ということもあって,売れる本ではないのでまだまだ先になりますが,増刷になれば,その時点で現在のファイル名に修正したいと思います.『統計的問題解決入門』でも,「はなこさん」のデータが執筆時点と変わってしまい慌てた経験がありますが,e-Statのファイルを使うのも問題あること実感しました.ご指摘に感謝します.
本日はこれにて.
P.S.
JMPの本は売れないということでは,この間も同じようなことを書いた記憶があるのですが,先日,神田の三省堂に出かけたので,統計ソフトのコーナーにも立ち寄ってみました.JMPの本は5種類各一冊づつしかありませんでしたけれど,そのうち2冊が私の本だったのは,嬉しさと寂しさが混じった気分でした.個人的にはSPSSには負けたくないという意味不明なライバル意識のようなものも持っているのですが,三省堂には「SPSSの本」というPOPまであって少々悔しい気もしました.

コメント