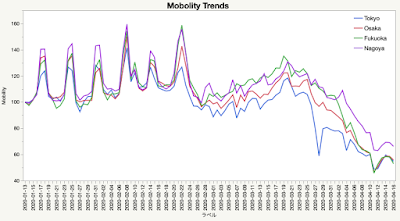
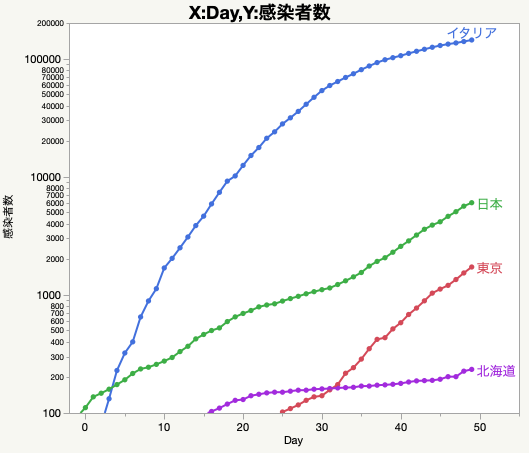
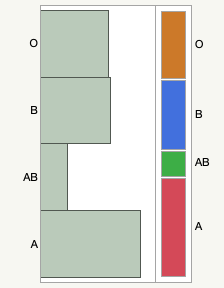
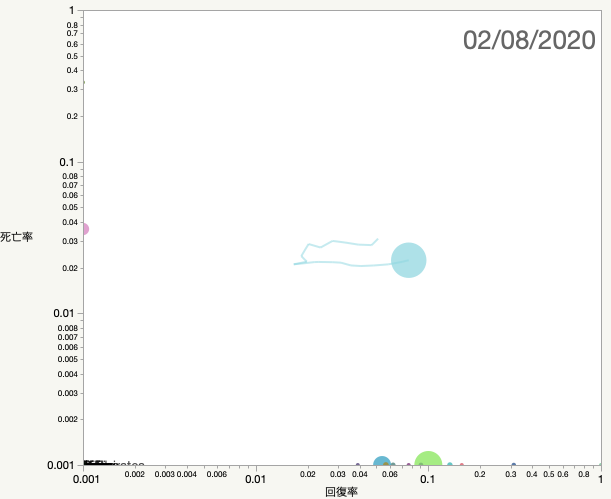
 JMP
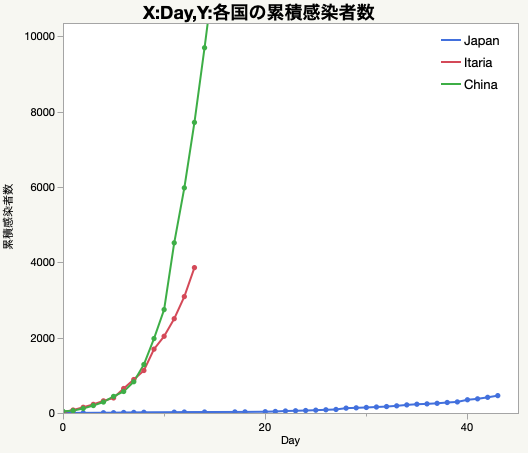
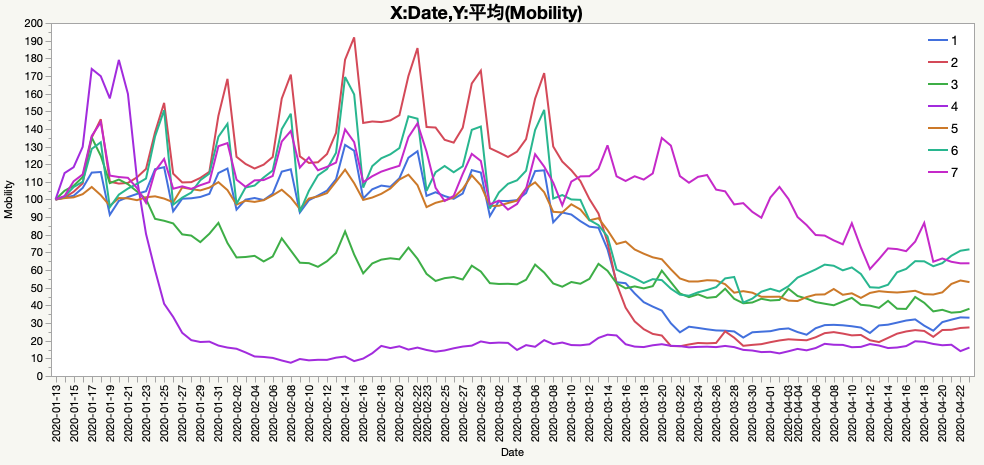
JMP見習うべきは台湾ではないか?
Amzonでは,日常必需品の発送を優先しているとかで,先日,岩波新書編集部がTweetされてましたけど,書籍のような生活必需品でないものの在庫切れが目立ってきているようです.拙著も,現在両方とも在庫切れになっていて,『統計的問題解決入門』の方は,しばらく前から入荷時期未定になっていました.絶版になったわけではなく,実は,目出度く第3刷が増刷されたばかりなのです.流通が止まっている今は仕方ありませんね.連休中に勉強したいという方は,オーム社の直販を利用してくださいとのことです.第二刷では色々修正入れましたが,今回は大きな修正はありません.とはいえ,何点か変更した箇所もありますので,そのうちこの場...