
ライフスタイルが変わるから更新頻度も変わるかなって思ってたけど,結局のところ週末更新に落ち着いてます.リモートワークともおさらばとも期待してたけど,それも今まで通りという現実.コロナ感染が拡大してきているから,まあそれは良かったんだけど.あ,ちなみに今の状況はそれほど心配してないです.いつか紹介した,ECMOnethttps://crisis.ecmonet.jpの「COVID-19重症者におけるECMO装着数の推移」を見る限りでは,東京は4名で,これは8月上旬と同じレベル.日本全国でも17名なのでまだ大きくは変化してない感じです.人工呼吸治療数は緩やかに増加しているけど,感染者が増えればそうなるだろうな.
さて,今日はSummit Japanについて書こうかと思います.いよいよ来週開催になったけど,例年と違って全く緊張感なくて拍子抜けしてます.SASの皆さんとは比較にならないけど,毎年この時期になると落ち着かない毎日でした.自らが発表した年はもちろんだけど,プレミーティングでスピーチをしなくちゃならなかったり,何かとやることがあった.去年はサインの練習をした記憶がある.そもそも大勢の人と会うと考えただけでも緊張したものです.今年は発表者ではあるけど,もうビデオ収録しちゃったからやることもないし.
リアルタイムでZoom収録された方もいるみたいだけど,自分のはiPadを使った完全にホームメイドです.アメリカの発表は,ほぼ全てがZoom録画のような感じでした.共有画面の右上に発表者の顔が小さく写ってるやつですね.発表者の顔はわかった方がいいけど,常時写ってる必要はないと思って,自分の発表では最初と最後にピクチャーインピクチャー(PIP)しました.普段のオンラインセミナーの感じに仕上げたつもりです.
言い間違いとか簡単に訂正できるから,ある意味楽だったけど,今になってプレッシャーを感じてます.リアルタイムの発表は恥は一時で済むけど,ビデオ収録した発表は後に残るからね.自分で何を話したかが確認できるのが辛いです.見直してみると,説明が不十分なところ多々あります.30分に時間を調節するために,あちこちカットしたもんね.JMP操作についてはかなり端折ったけど,この事例では少しだけトリッキーな操作が必要です.ご覧になって詳細が知りたければコメントください.
JMP Proの関数モデルエクスプローラ(FDE)のデモ事例だけど,非常に単純な事例なので,これだけでチュートリアルになるとは思ってないし,そもそもその意図もないです.FDEってこんなものかってのが伝わればいいかなと.この事例でも最適化はできてないわけで,FDEを使えばすべてがうまくいくというわけではないです.SAS社の方とお話しして,FDEの有効性については結構ネガティブなご意見でちょっと意外だったけど,JMPerとしては今までRとMATLABでしか試せなかった処理がJMPでできるようになったのは素直にありがたいです.この発表に際して調べたところでは,PythonやSASにも実装されてるらしい.
いつかも書いた記憶があるけど,今回の発表のLevelがJMPマーク三つ(最高難易度)になってるのはJMP Proの機能を使っているからで,内容そのものは特に難しい内容ではないです.ということで,まだの方はこちらから登録して,よろしければご覧になってください.https://discoverysummit.jmp/ja/2020/japan/register.html
関数データエクスプローラの事例としては,おそらく,Session ID: 2020-JA-30MP-22の「JMPの多変量解析ツールを使ったスペクトルデータの分析」のほうが適してます.いろいろなツールを使ったスマートな事例です.これは,USのSummitで発表された「Using Multivariate Tools in JMP® for Analysis of Spectral Data」 (2020-US-30MP-636)と同じですね.既に聴講したんだけど,自分の英語力だと理解が覚束なかったので,今回,日本語音声が入るというので聞きなおしてみよう.
Summit USを聴講したときのメモ書きをご参考まで.
いろいろな機能を使いこなしている.勉強不足を実感.「関数実験計画分析」は試してみる価値大.関数主成分の一般化回帰を実施.関数主成分を共変量としてカスタム計画を作成.選択された行のサブセットでPLS回帰を実行,VIP(変数重要度)をもとに因子抽出.弾性ネットも適用.モデル式は確かにシンプルだが,従来モデルとの違いがわからない.デモデータが不適当なのかも.
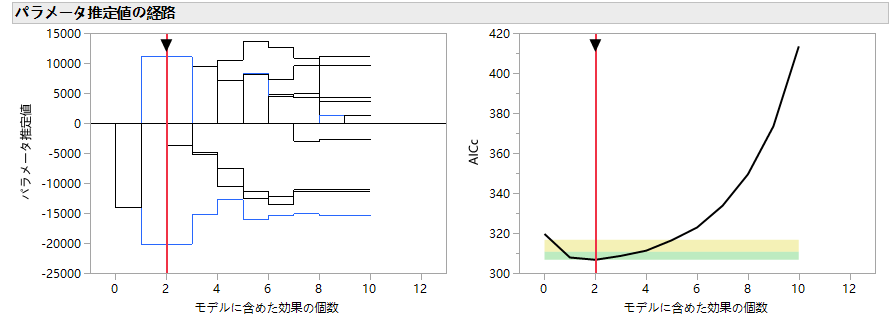
「関数実験計画分析」というのが,赤三角にあるのは気付いてはいたんだけど,設計因子のプロファイルまで出力してくれるんですね.自分のデモ事例では深くは掘らなかったので,普通に「モデルのあてはめ」を使ったのがが悔やまれます.参考までに画面を載せときます.
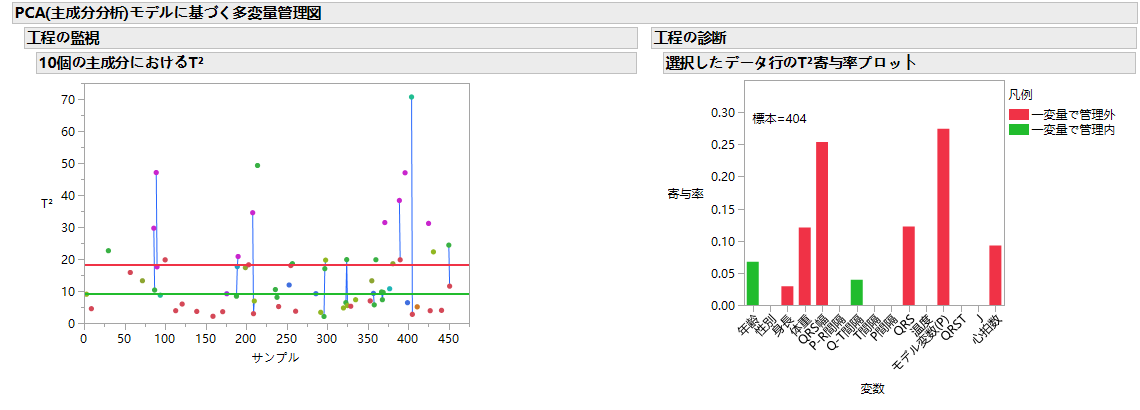
多変量管理図(MDMCC)も使ってました.JMP15から実装されたことは知ってたけど,ここまで使えるとは思ってなかった.主成分分析で管理図を描いてくれるんだけど,グラフレットが実装されていて,新しいプラットフォームであることがわかります.これは工程管理以外にも使える強力なツールになると予感.有名な不整脈のデータ(UCIの機械学習データセットでJMPのサンプルデータにもある)で試してみたのがこちら.T2最大の被験者を選択して寄与率プロットを出してみました.
発表者のBill WorleyさんはJMP Senior Global Enablement Engineerとのことで,https://www.jmp.com/en_sg/bios/worley-bill.htmlによれば,P&Gにいらっしゃったとのこと.BASF やUnileverにも在籍していたように書かれているから,バリバリの化学畑の方みたいです.化学分野ではスペクトルデータの解析にPLS回帰をよく使うけど,その代わりに関数データエクスプローラと実験計画の共変量の機能を使った新しいアプローチを紹介する,と要旨にあります.
この発表がLevel2なのは,やはりおかしい.発表者の相対評価だからでしょうか.聴講者のためには絶対評価にすべきです.来年もステアリング委員を拝命するなら,この点は改善提案しようと思います.ただ,いろいろ難しい問題もあって,当人がLevel3と思ってる内容に,こちらからLevel1だとは言えないですよね.何からのガイドラインがあればいいんだけど.
その昔,質量分析装置を設計していたので,スペクトルデータの検量にはPLS回帰が有効というのは知っていました.今回のデータは近赤外分光スペクトルなので,波形処理と機械学習を使ったフィンガープリント法とか発達してるから,実務的にFDEがどれだけ有効なのかはよくわからないです.Bill Worleyさんも,こんなきれいなスペクトルは実務ではあまりないので,スペクトルの前処理について課題としてあげられてました.自前のデータがあるかたはトライしてみて欲しいです.当時JMP15があればいろんなことができたのに,今それができる人は素直にうらやましいです.
なんか今日はとりとめもなくなっちゃいました.すいません.そのうちもっとちゃんとした解説をしてみたいとおもいますが,本日はこれで.それでは.

コメント